OCRText¶
OCRTextコンポーネントは画像からテキストを抽出します。
OCRTextコンポーネントのタイトルバーをダブルクリックし、OCR Settingsウィンドウを起動します。
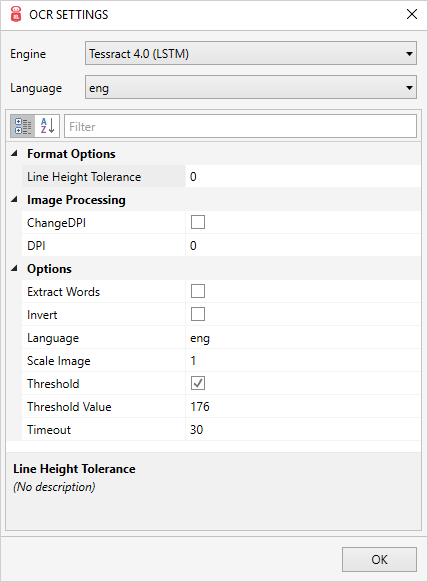
Engine(OCRエンジン): Intellibotスタジオは次のOCRエンジンの使用をサポートしています。- Tesseract 4.0(LSTM)
- Windows
- ABBYY
- Abbyy クラウド
- Google クラウド
- Microsoft クラウド
- Amazon クラウド
- Language(言語):選択したOCRエンジンでサポートされているすべての言語を表示します。
既定の言語は「英語」です。 - Search(検索):選択したOCRエンジンのプロパティを検索できます。
- Options(オプション):選択したOCRエンジンに基づいてさまざまなオプションを有効にします。
ポート¶
OCRTextコンポーネントは、既定でコントロール入力ポート、コントロール出力ポート、データ入力ポート、データ出力ポートを持っています。
| ポート | 説明 |
|---|---|
| Control In (コントロール入力) |
1つ以上のコンポーネントのコントロール出力ポートに接続する必要があります。 |
| Control Out (コントロール出力) |
他のコンポーネントまたはコネクタのコントロール入力ポートに接続できます。 |
| Data In (データ入力) - ビットマップ |
他のコンポーネントまたはコネクタのデータ入力ポートに接続できます。 |
| Data Out (データ出力) - 文字列 |
抽出されたテキスト(文字列)を返します。 |
プロパティ¶
OCRTextコンポーネントのプロパティを編集するには、プロパティ ウィンドウで、必要なプロパティを変更できます。
次のプロパティを編集できます。
| プロパティ | 説明 |
|---|---|
| Search | それぞれのプロパティを検索します。 |
| Delay After Execution | アクションが実行された後(秒単位)の待機時間を指定します。 |
| Delay Before Execution | アクションが実行されるまでの待機時間(秒単位)を指定します。 |
| Name | OCRTextコンポーネントの名前を指定します。 |
| Image Source | Image Source(画像ソース)には2つのオプションが表示されます: Port:画像の読み取り元となる別のコンポーネントに接続できます。 FilePath:保存された画像のFilePathを指定できます。 |
例¶
画像からのテキストを抽出する例を見てみましょう。

テキストを抽出するには:
まず、ReadFromFile コンポーネントを使用して、次のように読み取ることができる画像を OCR テキストに提供します。
ToolboxでUtilitiesを展開します。Image Utilitiesを展開します。ReadFromFileコンポーネントをドラッグして、デザインサーフェイスにドロップします。FilePathをダブルクリックし、保存した画像のファイルパスを記載します。OCRTextコンポーネントで画像をテキストに変換するには:ToolboxでActionsを展開します。OCRTextコンポーネントをデザインサーフェイスにドラッグアンドドロップします。
Showコンポーネントは抽出したテキストを確認するために使用します。Showコンポーネントを追加するには:- Generalを展開し、Showコンポーネントをデザインサーフェイスにドラッグアンドドロップします。
- 以下のコネクタを接続します:
StartコンポーネントとReadfromFileコンポーネント間のコントロールポート。ReadfromFileコンポーネントのコントロール出力ポート をOCRTextコンポーネントのコントロール入力ポートへ。ReadfromFileコンポーネントのデータ出力ポートをOCRTextコンポーネントのデータ入力ポート へ。OCRTextコンポーネントのデータ出力ポートをShowコンポーネントのデータ入力ポートへ。- Messageboxコンポーネントのコントロール出力ポートをEndコンポーネントのコントロール入力ポート へ。
Runをクリックします。- テキストの抽出が正常に行われると、次のようにメッセージボックスに表示されます。