PDF¶
PDFコネクタを使用すると、PDFドキュメント内で一般的に実行されるタスクを実行できます。PDFコネクタは、プロジェクトで使用できるさまざまなメソッドを公開します。
Note
PDFコネクタは既定のコネクタではなく、必要に応じてプロジェクトに追加する必要があります。
プロジェクトへのプラグインを追加する方法の詳細については、プラグインセクションを参照してください。
使い方¶
PDF コネクタをプロジェクトに追加後、手順に従って PDF コネクタにアクセスします。
- ツールボックスで
コネクタを展開します。

- PDFコンポーネントをドラッグし、
Global Objectsの下にドロップします。
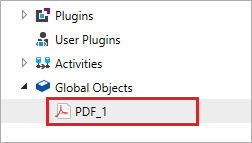
Global Objectsを展開します。Global Objectsの下のPDFコンポーネントをダブルクリックすると、オブジェクト エクスプローラー セクションに使用可能なPDF コネクタのすべてのメソッドが表示されます。
Load(ロード)¶
既存のPDFドキュメントを読み込むことができます。PDFドキュメントに対して他の操作を実行する前に、loadメソッドを使用しなければなりません。
入力:ファイルパス、パスワード
Close(閉じる)¶
PDFドキュメントを閉じることができます。
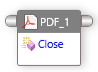
ExportAsImage¶
指定したページをイメージとしてエクスポートできます。このメソッドは、ページ番号を入力として受け取り、指定されたページをビットマップ イメージとして返します。
入力:ページインデックス
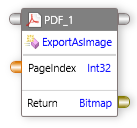
ExportAsImages¶
指定された範囲内のページのイメージをエクスポートできます。このメソッドは、開始ページと終了ページを入力として受け取り、ビットマップ配列内の出力イメージを返します。
入力:開始ページ、終了ページ
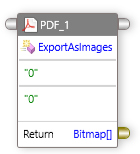
ExtractImages¶
既存の PDF ドキュメントからイメージを抽出できます。単一のページ、ページの範囲、またはドキュメント全体からイメージを抽出することを選択できます。このメソッドは、ページ インデックスを省略可能なパラメータとして受け取り、配列内のイメージを返します。
入力:ページインデックス
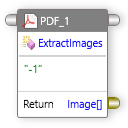
ExtractText¶
PDFドキュメントからテキストを抽出できます。単一のページ、ページの範囲、またはドキュメント全体からテキストを抽出することを選択できます。このメソッドは、ページ インデックスを省略可能なパラメータとして受け取り、文字列内のテキストを返します。
入力:ページインデックス
FindText¶
指定した PDF ドキュメント内のテキストを検索できます。このメソッドは、テキストを入力として受け取り、ブール値(True/false)を返します。
入力:テキスト
GetPageCount¶
PDFドキュメント内のページ数を返すことができます。このメソッドは、Loadメソッドで指定されたドキュメントを読み取り、ドキュメント内のページ数を整数として返します。
入力:ページインデックス
IsEncrypted¶
指定した PDF ドキュメントが暗号化されているかどうかを確認できるようにします。このメソッドは、ブール値を返します。
入力:ページインデックス
RemovePassword¶
既存のパスワードで保護された PDFドキュメントを復号化できます。RemovePasswordメソッドを使用する前に、Loadメソッドを呼び出してPDFドキュメントを開く必要があります。
Save(保存)¶
既存の編集可能なPDFドキュメントへの変更を保存できます。saveメソッドを使用する前に、まずloadメソッドを呼び出してPDFドキュメントを開く必要があります。
入力: ファイルパス
SetExportImageConfig¶
PDFドキュメントからエクスポートされるイメージのプロパティを定義できます。
入力: 幅、高さ、イメージ X 軸 DPI、イメージ Y 軸 DPI、イメージ縦横比
SetPassword(パスワード設定)¶
既存の PDFドキュメントをパスワードで暗号化できるようにします。SetPasswordメソッドを使用する前に、まずloadメソッドを呼び出して PDF ドキュメントを開く必要があります。