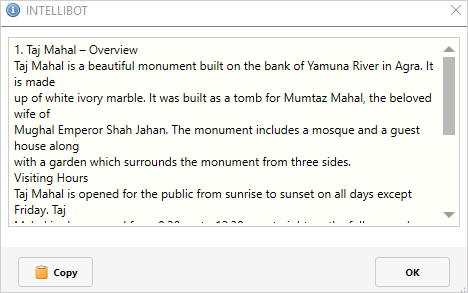
GetText¶
GetText コンポーネントを使用すると、PDFファイルからテキストを抽出できます。
サポートされている機能¶
GetText コンポーネントのタイトルバーをダブルクリックして、EXTRACTOR SETTINGSウィンドウを開きます。
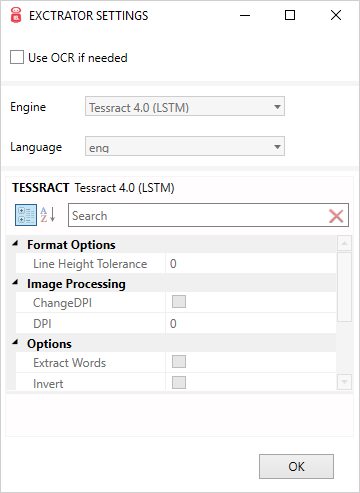
- 抽出するには、
use OCRのチェックボックスをクリックします。- リストから、OCRエンジンを選択できます。
- 商用OCRエンジンが一覧から選択されている場合は、資格情報を指定する必要があります。
(例:アクセスキー、シークレットキー、Apiキー、アプリケーションID、クラウドパスワード、ライセンスキーなど)
ポート¶
GetText コンポーネントは、デフォルトでコントロール入力、コントロール出力、データ入力ポート、およびデータ出力ポートを公開します。
| ポート | 説明 |
|---|---|
| Control In | 1つ以上のコンポーネントのコントロール出力ポートに接続する必要があります。 |
| Control Out | 他のコンポーネントのコントロール入力ポート、または既定のエンドコンポーネントのコントロール入力ポートに接続できます。 |
| Data In | GetText コンポーネントは、既定で次のデータ入力ポートを公開します。PdfFilepath: PDFファイルの場所を指定します。PageNumber: PDFファイルのページ番号を指定します。 |
| Data Out | PDFドキュメントのコンテンツを返します。 |
プロパティ¶
GetTextコンポーネントのプロパティを編集するには、Properties ウィンドウでプロパティを変更します。次のプロパティを編集できます。
| プロパティ | 説明 |
|---|---|
| Search | それぞれのプロパティを検索します。 |
| Delay After Execution | アクションが実行された後の待機時間(秒単位)を指定します。 |
| Delay Before Execution | アクションが実行されるまでの待機時間(秒単位)を指定します。 |
例¶
例を見てみましょう。
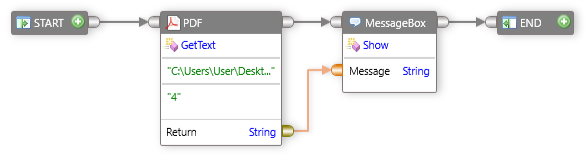
PDFファイルからデータを抽出するには、次の手順を実行します。
- ツールボックスで、
Utilitiesを展開し、次にPDFを展開します。 GetTextコンポーネントをドラッグし、デザインサーフェイスにドロップします。PdfFilepathボックスをダブルクリックし、パスを入力します。- ページ指定での抽出用にPDFファイルのページ番号を指定できます。
- 既存のデータソースを上書きするには、
PdfFilePathを右クリックします。 -
overrideをクリックし、データソースを変更します。Note
データポートのデータソースの上書きについての詳細については、オーバーライドセクションを参照してください。
-
GetTextタイトルバーをダブルクリックすると、EXTRACTOR SETTINGSウィンドウが開きます。
- チェックボックスをクリックし、OCRエンジンをリストから選択します。
商用OCRエンジンを使用する場合は、必要な資格情報を提供する必要があります。
(この例では、OCRエンジンの種類として "Windows" を選択しています)。 OKをクリックします。- メッセージボックス
Showコンポーネントをドラッグし、デザインサーフェイスにドロップします。 - アクティビティでコントロールポートとデータポートを接続します。
- ツールバーで、
Runをクリックします。